The Data Explorer Data Prompter is a stand-alone, Motif-based user interface for importing data. It consists of three dialog boxes:
The general purpose programs used by the Data Prompter may be found in /usr/local/dx/ui, with names denoting the type of data they visualize. You may find these programs useful on their own (apart from their use in the Data Prompter).
Data Explorer Format | The Data Explorer format can be used to describe any object which can be represented in Data Explorer. Objects can be exported in the Data Explorer format using the Export module, and often filters are written to convert from other formats to the Data Explorer format. The Data Explorer format is described in detail in B.2 , "Data Explorer Native Files" in IBM Visualization Data Explorer User's Guide. The Data Explorer format is supported directly by the Import module (see Import IBM Visualization Data Explorer User's Reference). To create visual programs using data in this format, simply use the Import module, specifying the file name, and the format as "dx". |
CDF Format | CDF is a standard format, supported directly by the Import module. For more information on the CDF format, see B.3 , "CDF Files" in IBM Visualization Data Explorer User's Guide. To create visual programs using data in this format simply use the Import module, specifying the cdf as the name parameter to Import, and specifying the format as "cdf". |
netCDF Format | netCDF is a standard format, supported directly by the Import module. For more information on the netCDF format, see B.4 , "netCDF Files" in IBM Visualization Data Explorer User's Guide To create visual programs using data in this format simply use the Import module, specifying the file name as the name parameter to Import, and specifying the format as "netCDF". |
HDF Format | HDF is a standard format, supported directly by the Import module. Data Explorer supports HDF files that contain a Scientific Dataset (SDS). For more information on the HDF format, see B.6 , "HDF Files" in IBM Visualization Data Explorer User's Guide. To create visual programs using data in this format simply use the Import module, specifying the file name as the name parameter to Import, and specifying the format as "hdf". |
Image data | Images in TIFF, MIFF, GIF, and RGB formats can be directly imported by the ReadImage module (see ReadImage in IBM Visualization Data Explorer User's Reference). To see the image, you need only to attach the output of ReadImage to first input of the Display module. You can of course manipulate the image with any of the appropriate Data Explorer modules. |
Grid or Scattered Data (General Array format) |
Data Explorer can import a wide variety of gridded and scattered data using the General Array format. The basic procedure is to create a header file which describes the structure of the data (dimensionality, number of variables, layout in the file, etc.). The General Array Importer is described in detail in 5.1 , "General Array Importer". 5.2 , "Importing Data: Header File Examples" contains many examples illustrating the wide variety of data that can be imported. The Data Prompter greatly simplifies the task of creating a header file, as it performs extensive error checking (disallowing conflicting keywords, for example) and frees you from needing to know the exact syntax of the General Array format. When you use the Data Prompter to import this format, you will be asked to describe your data in detail. You need to then save the header file using Save As in the File menu of the Data Prompter Full or Simplified window. The data can then be visualized using one of the general purpose programs provided by the Data Prompter. To create new visual programs using data imported in this way, simply specify the name of the header file to the Import module, specifying the format as "general" (see Import in IBM Visualization Data Explorer User's Reference). |
Spreadsheet Data | Spreadsheet data is typically non-spatial data, arranged in columns. This type of data is supported by the ImportSpreadsheet module (see ImportSpreadsheet in IBM Visualization Data Explorer User's Reference). |
Note: For the formats directly supported by Import (Data Explorer, CDF, netCDF, HDF) or ImportSpreadsheet (spreadsheet data), it is not necessary to use the Data Prompter to import the data. You can simply use the Import or ImportSpreadsheet module and then add whatever visualization modules you want to look at the data. However, you can use the Data Prompter to give you easy access to the general purpose programs which get you "up and running" with a picture of your data.
If you are importing your data using the General Array format, once you have created a header file (typically done by using the Data Prompter), you can import the header file directly using the Import module.
To start the Data Prompter, type:
dx -prompteror choose Import Data from the Data Explorer Startup window. The initial dialog box appears (see Figure 15).
Figure 15. Initial Data
Prompter window
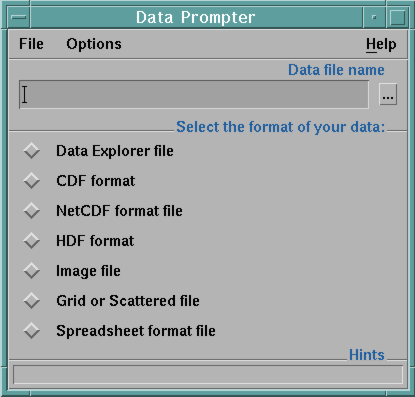
At the top of the Data Prompter initial dialog is a text field into which you can enter the data file to be imported. If you press the ... button to the right of the field, a list of directories is presented. This list of directories is taken from your DXDATA environment variable, if set (see C.1 , "Environment Variables" in IBM Visualization Data Explorer User's Guide). Then a file selection dialog is presented, initialized to the directory chosen from the ... button. You can also access the file selection dialog directly by choosing Select Data File from the File menu.
The dialog also allows you to specify the type of data file you wish to import. The choices are:
If you choose Image file, the dialog will expand, allowing you to choose the type of image format, and you can then have Data Explorer automatically read and display your image file.
If you choose Spreadsheet format, the dialog will expand, allowing you to specify whether to import the data as a table or a matrix. Spreadsheet data consists of columns of related data, typically non-spatial. If imported as a table, then the data will be treated as a single Field of data, with each column placed in the field as a named component. Each component will contain scalar or string data. If imported as a matrix, then it is implicitly assumed to be a two-dimensional grid, with the rows and columns specifying the two dimensions. In this case the data in each column must be of the same type (i.e. you cannot have mixed strings and numbers). The Spreadsheet format option also allows you to specify a column delimiter. For example, to specify tab-separated columns, specify "\t" as the delimiter. See ImportSpreadsheet in IBM Visualization Data Explorer User's Reference for more information.
If you choose Grid or Scattered File (General Array Format), which allows you to import a wide variety of data formats, you will need to tell Data Explorer more about the file. If you choose this option, the dialog box that appears allows you to identify for the Data Prompter five important characteristics of the data you want to import:
Grid type | Four grid-selection buttons display patterns representing different types of data. Reading from left to right, they are:
|
Number of variables | The stepper button allows you to specify the number of variables in the data file to be imported. For example, if the file contains data values for temperature and velocity (and for nothing else), the stepper button should be set to 2. (The default is 1, and the allowed range is 1-100.) |
Positions in data file | This option is available only with the selection of warped regular grid or scattered points. It is not meant for files that "describe" data positions by reference to origin-delta pairs. For example, if the data are organized as:
x1, y1, data1
x2, y2, data2
. . .
the toggle should be activated. Selecting the regular or partly regular grid automatically deactivates the toggle: the label is grayed out, and the button cannot be activated. Selecting the third button (warped grid) automatically activates the toggle, and a stepper button appears for setting the number of dimensions (e.g., set the stepper to 3 for x,y,z points). Once the warped grid is selected, however, the toggle cannot be reset (i.e., the position specifications are assumed to be in the file). Selecting the fourth button (scattered points) does not activate the toggle, but it allows you to do so, and to deactivate it even after setting the number of dimensions. |
Single time step | This toggle button allows you to specify whether your data consists of a single time step or not. By default, the toggle is activated. |
Data organization | The data organization can be characterized as block or spreadsheet. For example, given a regular grid containing two variables (say temperature and pressure), block style lists one set of values first, followed by the other:
t1, t2, ..., tn, p1, p2, ..., pn
Spreadsheet style alternates the two (one pair per line):
t1, p1
t2, p2
...
tn, pn
|
Once you have specified the five characteristics in the initial dialog box, click on Data Prompter. The simplified Data Prompter that appears is "customized," containing only those options appropriate to the data you have described in the dialog box (see "Simplified Data Prompter").
For Future Reference: Once you have opened and modified either the simplified or full data prompter, if you then close the simplified or full window, you should not use the Describe Data button to reopen the window, as the Describe Data button opens a brand new window. Instead, use Open General Array Importer from the Options menu of the initial dialog.
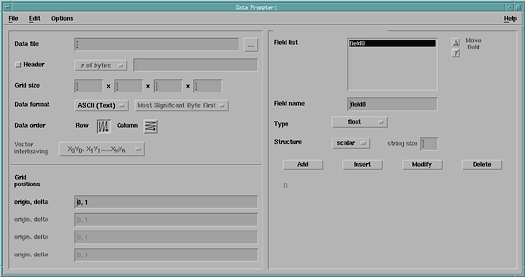
The simplified Data Prompter (Figure 16) is just what its name implies: a smaller version of the full Data Prompter (Figure 17). It displays a subset of the buttons, parameters, and fields contained in the larger version. Since these are identical in both versions, they are described in the section on the full Data Prompter (see "Full Data Prompter").
This section instead describes only the menu bar and its options, which are also identical in both the simplified and full prompters.
Figure 16. Simplified Data
Prompter. This window contains a subset of the buttons, parameter, and
fields available in the full Data Prompter (see Figure
17). The Options pull-down menu can be used to call up the full prompter or
to return to the initial dialog box.
The Data Prompter menu bar displays four options: File, Edit, Options, and Help.
The following functions are available in this pull-down menu:
New | Resets the Data Prompter by setting all fields to their default values. |
Open... | Invokes a standard Motif file-selection dialog box that prompts for a choice of file. You can read in an existing General Array Importer header file, whether or not it was created with the Data Prompter. However, the Data Prompter does not support header files containing the data to be imported: the data is assumed to exist in a separate file. To read an existing header from a file that also contains the data to be visualized, the header should be written out to a separate file. |
Save | Writes the Data Prompter header file out, using the current file name. The current file name is set by opening a file or by executing the Save As... command. The Data Prompter will check the correctness of most aspects of the header file to be saved. Any problems are reported and the Save operation is terminated. You may then correct the indicated problem and save the header file again. |
Save As... | Is the same as Save except that you must specify a name for the header file. |
Quit | Terminates the Data Prompter application. It also gives you the option of saving any changes not already saved. |
Edit has one option: the Comment dialog box.
Comment... | Displays a text dialog box for entering comments about a header file. These comments are stored with the file and are ignored by the General Array Importer. Any comments it contains are displayed in the Header Comment dialog box. |
The following options are available in this pull-down menu:
Full prompter | Invokes the most detailed prompter dialog box (Figure 17). It can also be invoked from the command line: dx -prompter -full. |
Simplified prompter | Invokes a prompter dialog box (Figure 16) that is less detailed than the full Data Prompter. |
Initial dialog | Invokes the initial dialog box (Figure 15). It can also be invoked from the command line: dx -prompter. |
This pull-down menu contains one option not available in the corresponding pull-down menus of the VPE window, the Image window, and the Data Browser:
On General Array Format... | Displays the online documentation of the General Array Importer format. |
The full Data Prompter dialog box is divided into halves, the left half describing features of both the data file and the data, and the right half describing the data field(s) (see Figure 17). The order of descriptions in this section follows that of the dialog box: from top to bottom in the left half and then top to bottom in the right half.
Note: If you used the initial dialog box to describe your data and then selected OK instead of Full, you are in the simplified Data Prompter and some options may not be presented. However, you can invoke the full prompter at any time by selecting it in the Options pull-down menu.
Data file |
The first information the General Array Importer requires is the path name of the data file to be imported. This name can be entered directly in the text field to the right of the Data file label. Alternatively, you can click on the ellipsis button (...) to the right of the text field. If you select File Selection Dialog... from the pop-up menu, you can select a file from the dialog list. Note that using the File Selection dialog list is simply a shortcut for typing in the path name. The Browser option on the ellipsis pop-up is discussed in 5.5 , "Data Prompter Browser". See also "file". Figure 17. Full Data
Prompter. The two halves of this dialog box are described in separate
sections in the text (see "Data File and Data
Information" and "Data Fields Information"). 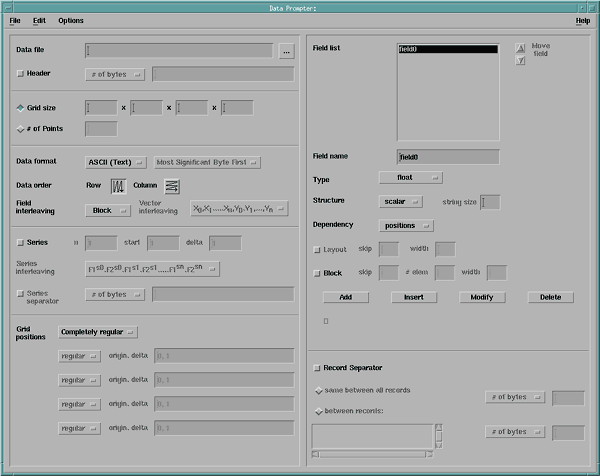 | ||||||
If your data file has a header (an initial section that must not be imported with the data), activate the Header toggle button. Clicking on the button immediately to the right of the toggle will generate a pop-up menu of three options for specifying where the header stops and the data begins:
See also "header". | |||||||
Grid Size versus # of Points | Located below the Header toggle button are two buttons labeled Grid Size and # of Points. If the data has connections that are gridded, click on the Grid size button. Specify the dimensions of the grid in the associated text fields (e.g., if the data are 2-dimensional, enter the sizes in the first two fields and leave the last two blank). If the data consist of unconnected points, click on the # of Points associated button, and enter the appropriate number in the associated text field. Notice that these choices affect other aspects of the Data Prompter. The choice of points deactivates the Data order buttons and all but the first origin-delta field in the Positions section at the bottom. | ||||||
Data Format | The format of the data can be ASCII/Text or Binary/IEEE. The selection of Binary/IEEE) activates the Significant Byte First option button immediately to the right. You may then select Most Significant Byte First (MSB) or Least Significant Byte First (LSB). For ASCII (or Text) format, this option button is inactivated. See also "format". | ||||||
Data Order | This option specifies the layout of multidimensional arrays. Row (majority) means that the last index of a multidimensional array varies fastest (as in C language). Column (majority) means that the first index varies fastest (as in FORTRAN). See also "majority". | ||||||
The data to be visualized must be organized in one of two general styles: block or columnar. For data laid out in blocks, select Block from the Field Interleaving option menu. For columnar style, select Columnar. Note that when Columnar is selected, both Vector Interleaving and Series Interleaving are grayed out. (See "Some Notes on General Array Importer Format" for more information about the block and columnar styles.) See also "interleaving". | |||||||
Vector Interleaving | The interpretation of vector data organized in records (blocks)
is
specified by the Vector Interleaving
option button.
The two choices in the associated option menu are:
"Vectors together" means that all of the components of one vector are written together, then all the components of the next vector, and so on. "Components together" means that all of the x-components are written together, then all the y-components, and so on. See also "interleaving". | ||||||
Series | For data consisting of a sequence of fields, click on the Series toggle button, activating the three text fields to the right:
See also "series". | ||||||
Activating the Series toggle button
also
activates the Series Interleaving option
menu if Field Interleaving is set to
Record.
The option menu contains two choices:
This feature is useful for series that consist of more than one field. "Series members together" means that the data for each field of series member zero (s0) are followed by all the data for each field for series member one (s1), and so on. "Fields together" means that all the series members for field 1 (F1) are followed by all the series members for field 2 (F2), and so on. See also "interleaving". | |||||||
This feature is required only if the data for series members are separated from one another by non-data (e.g., comments). The specification is identical to that of the Header keyword (see Header). See also "series". | |||||||
Grid Positions | This feature is required for gridded data if you have not specified that the positions are stored in the file (by naming one of the fields with the reserved word "locations"). The entire section is grayed out if the "locations" reserved word is used. If the data consist of unconnected points (and are so specified in the initial dialog box or by the # of points toggle), all but one of the origin-delta fields is grayed out. See also "positions". The option button just to the right of the Grid positions (or Point positions) title offers the following choices:
|
Note: A change made in any option in this part of the dialog box generates an instruction to save (confirm) the change by clicking on the Modify button at the bottom of the panel.
Field List | This list (at the top right of the Data Prompter) displays the names of the fields that are currently defined for a header file. If the list contains more than one field, their order must match that of the fields in the data file. To change the order of the fields, use the Move field arrows, after first selecting (highlighting) the field name to be moved. Note that the settings of the various buttons and associated text fields below the field list are updated whenever a field is selected. See also "field". | ||||||||
Field name | The text field immediately below Field List displays the name of the current (selected) field. Field names must be unique. Default field names take the form "fieldn", where n is an integer. You can change a name and then click on the Modify button (near the bottom of the Data Prompter) to confirm the change. (Similarly you can add, insert, or delete a field. See Field List Buttons at the end of this section.) | ||||||||
Type | For each field in the list, select the appropriate data Type with the associated option button. The type must match that of the data in the field. The supported types are: double byte int short float signed byte signed int signed short string unsigned byte unsigned int unsigned short Note that:
Specifying string enables "string size," which should contain the length of the longest string. See also "type". | ||||||||
Structure | For each field in the list, select the appropriate Structure with the associated option button. Accepted values are scalar and 2-vector, ..., 9-vector. However, 5-vector, ..., 9-vector cannot be specified for column-majority arrays. See also "structure". | ||||||||
Dependency | For each field in the list, select the appropriate Dependency with the associated option button. The default setting of this option is "positions" (one data item per position). If the data in the field are cell-centered (connection dependent) select "connections". See also "dependency". | ||||||||
This option is automatically activated when the data in the current field are field-interleaved (columnar) ASCII (Text). It specifies the locations of data items in a line of text.
See also "layout". | |||||||||
This option is automatically enabled when the data in the current field are record-interleaved (block) ASCII (Text). It specifies the locations of data items in a line or field of text.
See also "block". | |||||||||
Field List Buttons | Four buttons at the bottom of the Data Prompter operate on the fields list:
Note: Modify and Delete are grayed out if there is no selected item in the field list. | ||||||||
Record Separator | This option is enabled only when Block field interleaving is selected. It allows you to specify a separator between blocks, or records, in the data file, when there are more than one. You can specify the same separator for between each record, or a different separator between each record. Depending on the setting of Vector interleaving button, separators may be specified between each field, or between each component of each vector in each field. |
![]()
![]()
![]()
![]()
[ OpenDX Home at IBM | OpenDX.org ]